How to Scrape Google Search Results in 2025
In today’s data-driven world, scraping Google search results is an incredibly powerful technique for SEO analysis, market research, and competitive intelligence.
However, as we move into 2025, Google’s anti-scraping measures continue to evolve, making it more important than ever to take a careful, ethical, and technically sound approach.
In this guide, we’ll break down the best ways to scrape Google search results in 2025, the tools you can use, and the best practices to ensure you do it safely and effectively.
Key Takeaways
- Use headless browsers, scraping APIs, or Python scripts.
- Scraping Google can violate its Terms of Service- consider using compliant APIs.
- Rotate proxies, use human-like browsing behavior, and limit request frequency.
- Google changes frequently—update your scraper as needed.
What Is Google Search Scraping?
Before we proceed, let us really dive into what it means to scrape Google search results.
Scraping Google search results is basically a process of using automated tools to collect and extract data from Google’s search pages.
This data could be page titles, URLs, snippets, and meta-data and they can be useful for:
- SEO Research: SEO (Search Engine Optimization) is all about optimizing web pages to rank higher on search engines like Google. Scraping Google search results can provide critical insights into keyword performance, search trends, competitor rankings, and also featured snippets & SERP features.
- Market Analysis : This is understanding your competitors’ online presence, and it is very crucial for staying ahead in your industry. Web scraping allows businesses to analyze competitor visibility and strategies, monitor competitor rankings, track advertising trends, and identify market gaps.
- Content Creation: While this is always a powerful strategy, creating content blindly is not always effective. Scraping Google search results helps content creators to gather insights for content planning by finding popular topics, analyzing top-performing content, extracting related keywords, and optimizing for search intent.
- Business & Academic Research: Data-driven decision-making is important in both business and academia. Scraping search results can help researchers and professionals collect data for studies and reports, analyze public sentiment, collect data for AI & machine learning models, and conduct academic research.
However, Google actively works to prevent scraping, so it’s important to use proper methods and follow ethical guidelines.
The Best Tools You Can Use To Scrape Google Search Results in 2025
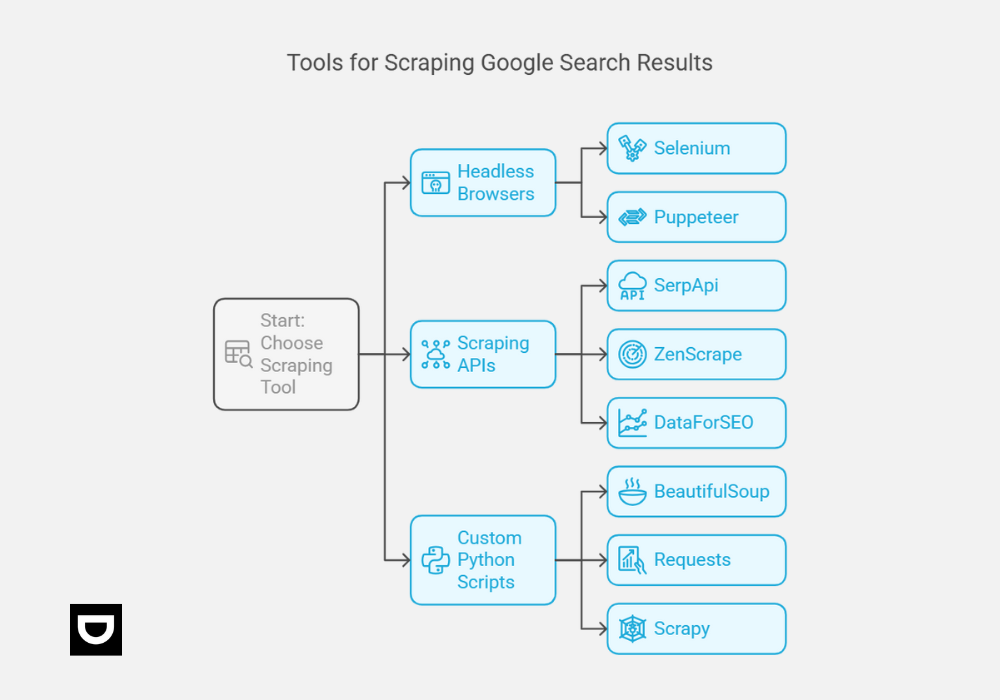
1. Headless Browsers
Headless browsers are web browsers that run without a graphical interface.
They allow scrapers to mimic real user behavior, making them highly effective for handling Google’s dynamic search results.
They are best used for scraping JavaScript-heavy pages and the popular tools to use are:
- Selenium
- Puppeteer
Pro Tip: If you’re comfortable with Node.js, use Puppeteer. If you prefer a more flexible solution, Selenium is a great choice.
2. Scraping APIs
These, on the other hand, are bets for hassle-free, scalable scraping and the popular tools to use are:
- SerpApi
- ZenScrape
- DataForSEO
Using a scraping API is often the easiest and safest way to extract search results. These services handle proxies, CAPTCHAs, and legal compliance for you.
They basically save you time and effort.
Pro Tip: If you need high-volume data extraction, an API is the most efficient option.
3. Custom Python Scripts
Custom Python scripts are best for maximum control over data extraction.
Popular libraries may include:
- BeautifulSoup
- Requests
- Scrapy
Python is an excellent choice for developers who want a more tailored approach, BeautifulSoup and Requests work well for simple scraping tasks, while Scrapy is better for larger projects.
Pro Tip: Add error handling and retry mechanisms to ensure your scraper adapts to unexpected changes in Google’s layout.
Step-by-Step Guide: How To Scrape Google Search Results
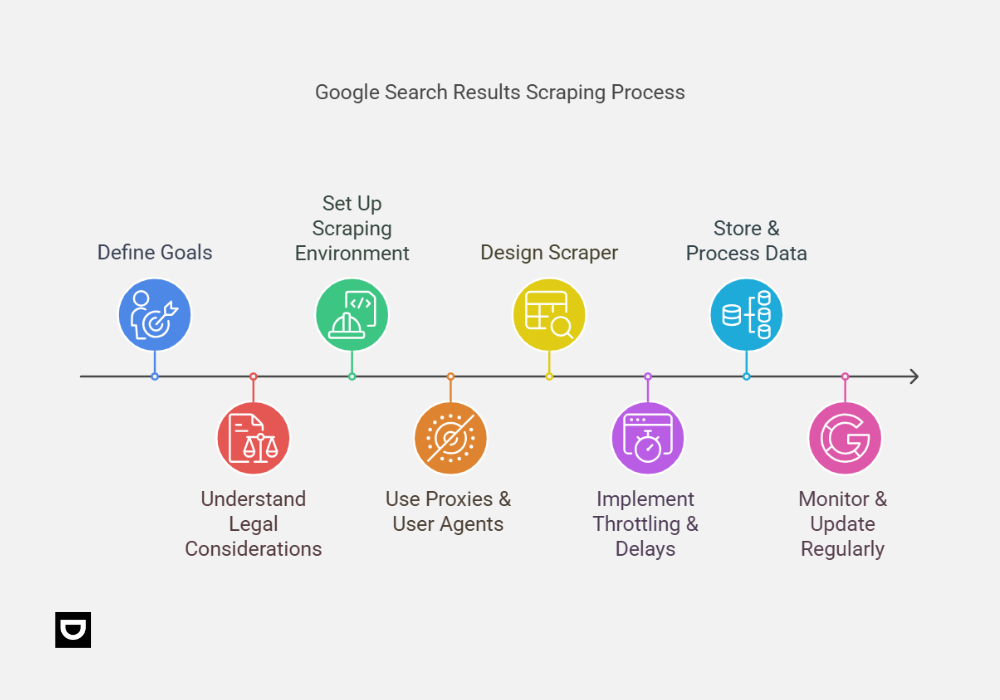
1. Define Your Goals
Defining your goals is important in scraping Google search results effortlessly.
You need to ask yourself these two questions:
- What data do you need?
- How will you use it?
Defining clear objectives will help you choose the right tools and stay within legal guidelines.
2. Understand Legal Considerations
Scraping Google can violate its (Google’s) Terms of Service, so it’s important that you stay informed about the legal guidelines.
Instead of just sticking to any kind of APIs, consider using APIs that comply with Google’s policies.
3. Set Up Your Scraping Environment
Prepare the tools that you will be needing for scraping and make sure to have them handy. These preparations may include:
- Installing Python (or Node.js for Puppeteer).
- Installing necessary libraries like requests, beautifulsoup4, scrapy, or selenium.
4. Use Proxies & User Agents
If google detects repetitive scraping requests, it would try blocking it.
In order to avoid being detected, it is necessary to take the following measures:
- Rotate IP addresses using a proxy service like ProxyMesh.
- Randomize user agent strings to mimic real browsing behavior.
5. Design Your Scraper
Designing an efficient and reliable web scraper requires careful planning and execution. If you do not plan it out properly, you will not execute it well either.
A well-designed scraper consists of multiple components that work together to extract data while minimizing the risk of detection or being blocked.
Listed below are the steps in designing your scraper:
a. Send Requests
Before you can extract any data, your scraper needs to send a request to Google’s search engine to retrieve search results.
This is typically done using an HTTP request.
How This Works:
- Your scraper will mimic a real browser by sending an HTTP request to Google’s search URL with a query (e.g., “best smartphones 2025”).
- Google will respond with an HTML document, which contains the raw data displayed on the search results page.
The best tools for sending requests are:
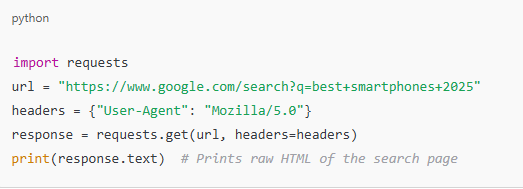
- Python (Requests Library)
This is a lightweight and simple way to request web pages.
Google often blocks automated requests, but using headers like “User-Agent”: “Mozilla/5.0”, makes the request look like it’s coming from a real browser.
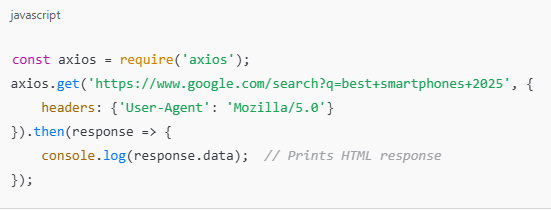
- Node.js (Axios Library):
This is a JavaScript-based alternative.
b. Extract Data
Once you’ve received the HTML page, the next step is to extract useful data from it. The goal is to locate elements like page titles, URLs, and Snippets.
How This Works:
Most programming languages have libraries that allow you to parse the HTML document and extract specific elements.
Tools for Extracting Data:

- Python (BeautifulSoup for HTML Parsing) It’s an easy-to-use library for parsing HTML and extracting elements.
- Node.js (Cheerio for HTML Parsing)
It allows you to extract elements from HTML quickly, similar to jQuery.

c. Handle JavaScript
Many modern web pages, including Google search results, load content using JavaScript.
This means that traditional scraping methods (like Requests and BeautifulSoup) may not work, because the initial HTML response won’t contain the full content.
How to Handle JavaScript-Rendered Pages?
You need to simulate a real browser to let JavaScript execute before extracting data.
This is where headless browsers like Puppeteer and Selenium come in.
- Using Puppeteer (Node.js)
Puppeteer is a headless version of Google Chrome that allows you to automate browser actions. These browser actions could be simply opening a page and extracting data after JavaScript executes.
Puppeteer fully loads JavaScript before scraping, and this makes it an awesome tool for dynamic pages.

- Using Selenium (Python)
Selenium is another headless browser automation tool that is commonly used for scraping JavaScript-heavy websites.
Unlike Puppeteer (which is Node.js-based), Selenium works with multiple programming languages (Python, Java, C#, etc.).

6. Implement Throttling & Delays
When scraping Google search results, you need to limit the number of requests you make in a short period of time.
This is because making too many requests in a short period can trigger Google’s anti-bot systems, and this can lead to temporary or permanent IP bans.
The only way to reduce the risk of detection, you need to slow down your requests and mimic real user behavior.
You can do this by:
- Adding randomized time delays between requests.
- Implementing rate limiting to mimic human browsing.
7. Store & Process Data
After you’ve scraped data from Google search results, the data needs to be stored in an organized format to be used later.
The most common storage options include:
- CSV Files – Simple and widely used for small datasets, easy to open in Excel or Python.
- Databases (SQL/MongoDB) – Ideal for large-scale data collection, allowing efficient querying and retrieval.
Also, you can use Pandas (Python) for data cleaning and analysis.
8. Monitor & Update Regularly
Google frequently updates its algorithms and search layouts.
You need to keep an eye on your scraper’s performance at all times and adjust your code as needed.
Best Practices to Avoiding Google Blocks
The best practices are still related to the steps which has been given already.
- Make use of rotating proxies & residential IPs.
- Randomize request headers & user agents.
- Ensure to add timeouts & delays between requests.
- Avoid scraping too many results at once so as not to be detected.
- Always monitor your scraper and adjust as needed.
FAQs
Is It Legal To Scrape Google Search Results?
Well, it is quite complicated.
Scraping public search results is generally allowed, but doing it excessively can violate Google’s Terms of Service.
To just be on the safer side. You can consider using APIs like SerpApi.
What’s the Best Tool for Scraping Google in 2025?
This depends on your needs actually. Figure out what your needs are and you can identify the best tools for you.
- Options for developers may include: Selenium, Puppeteer, BeautifulSoup.
- Options for hassle-free scraping may include: SerpApi, ZenScrape, DataForSEO.
How Can I Avoid Getting Blocked by Google?
While it is easy to get detected by Google and be blocked, you can also avoid this by:
- Using rotating proxies & residential IPs.
- Mimicking human browsing behavior with delays & realistic user agents.
- Using scraping APIs to handle compliance automatically.
Can I Scrape Google Without a Headless Browser?
If you’re only extracting basic static search results, yes.
However, for dynamic content, a headless browser is required.
What if My Scraper Stops Working?
Google updates its layout regularly so you need to monitor your scraper and update your code when necessary.
You can add error handling and logging to help you troubleshoot issues quickly.
Final Thoughts
Scraping Google search results in 2025 can be incredibly powerful, but it also comes with challenges.
It can be way easier though if you use the right tools, follow ethical best practices, and stay one step ahead of Google’s anti-scraping defenses.
Doing all these can help you unlock valuable insights without getting blocked.
At Dumpling AI, we specialize in automation solutions that make web scraping easier, smarter, and more compliant.
If you’re ready to streamline your data extraction process, try Dumpling AI today!
Happy scraping!





